Hello and welcome to Open Citizen Data Science!
Very often (one could say too often!) we keep hearing about this or that algorithm earning world-beating performance and accolades at some kind of problem solving.
While new, more efficient libraries are indeed a great way of improving performance, this tends to lead to a narrow definition of what makes a data scientist, often just being a glorified machine learning engineer.
Even worse, in my experience a worrisome trend is happening: the Data Science equivalent of what script kiddies are to hacking.
In order to understand this phenomenon we should remember the Data Science skill triad:
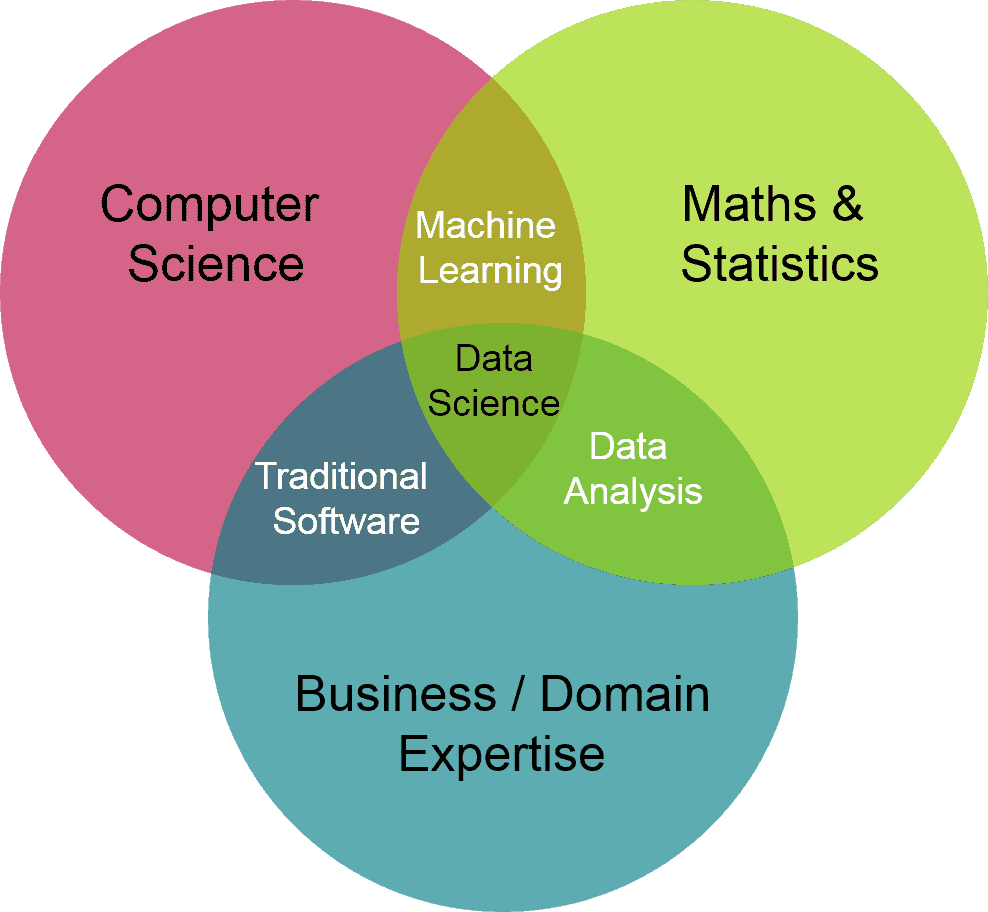
Now, the mentioned professionals often do not have the tools and the skillset to deal with the amount and complexity of data we deal with in data science as they either deal with single cases or work mostly with pre-cleaned and aggregate data, however they can and will give you extremely precious insights about possible anomalies, help spotting nasty issues like data leakage and often bring suggestions on how to shape new features for a dataset.
Tunnel vision: a common issue that can significantly impact productivity
Bringing together wildly different fields of expertise in a productive way is of course easier said than done. While collaborative approaches are in theory more efficient, there's always a cost to pay in terms of agility, meaning that in a short term view there is little time to listen (and is often limited to starting phase high level talk) and a focus on obtaining quick wins.
Even with this kind of limitations machine learning in most cases will still bring significant improvements from classical data analysis methods, as the ability of dealing with hundreds of KPIs in non-linear ways will produce stronger performance when set to a narrow enough objective. When measured in a synthetic way in the real world it's easy to match the claims of X times the classical method performance improvement, however this is just the model score prediction VS the target KPI and not the full picture.
In my personal experience, there are a few pitfalls that often prevents a model from being fully exploited once operational:
- Creating the prediction takes too long, meaning that a certain percentage of events will already have happened so they cannot be acted upon, This may or may not be remedied with better data engineering or narrower feature selection.
- The model is basing its scores on predictor variables that focus on customers that are hard to act upon. For example, in churn prediction a model might give a very high score on customers that queried the customer care about contract termination terms, meaning that either the customer has already been dealt with in a reactive way or is likely to already have made up its mind
- The model does not explain which KPIs are affecting the score on a single row, which means that finding the appropriate action will be time consuming or there's a risk of ineffective attempts.
- It might not be economical to act upon a large part of detected cases, meaning that either we can focus on the very top of the prediction (not a bad approach in itself) or the highest margin cases
- The dataset and sampling are made using "common wisdom", often derived from academia or sector studies, ignoring peculiarities of the dataset and leaving performance on the table. For example, 1 year of past data is often cited as the golden rule for churn prediction, however there are cases where performance doubled by using much shorter time frames!
While not critical failures on themselves, these factors means that a machine learning solution might have trouble in reaching a positive ROI even if it technically reached good results in accurately predicting the target KPI. Most of the times, this is the result of focusing purely on what is statistically correct while ignoring the wider context, a tunnel vision common in teams that are composed purely of data scientists and data engineers.
Using data democracy to improve your model part 1: Start with the right questions!
- Do not just find out the available data and the target variable, ask who is going to operationally use the model prediction and which actions are planned. This can both help on focusing the model on a smaller but better actionable sample and reduce training times
- Actions have a cost. No matter if it's sending a maintenance team or have customer care giving discounts, there might be significant portions of your population where a proactive approach could be too expensive. Finding out which parts can be prioritised can be used to help guiding the prescriptive part of a model or further focus your sampling
Using data democracy to improve your model part 2: Be modular!
- Start your development with a small model based on parts of the data most people are familiar with: this has the advantage of giving end users a prototype to familiarise with and start testing the operational phase. This can help the wider team to troubleshoot possible bugs with the data and give confidence on the project. Remember, even an half-working model often can give benefits over linear analysis!
- Divide your data wrangling by areas of expertise: find out who are the most familiar people with a certain set of KPIs and share your data cleaning and feature engineering approach with them: more often than not, they have valuable input on handling missing data and anomalies, plus this can allow you to create intermediate models showing how integrating that data source improves performance
Using data democracy to improve your model part 3: Use a white box and prescriptive approach
- Unless you're working with unstructured and non-text data, it pays off to show how the variables behave related to your target. If you're short on time you might just use a decision tree (works beautifully both for regression and binary classification plus can be moderately effective to explain a k-mean clustering), however if you're aiming for maximum clarity it might pay off to show how your target variable behaves with each class or bin of your features.
- Aiming for a prescriptive approach can also be useful: defining a set of available actions and potential triggers based on the model features can lead to an effectively impactful model, especially if it's able to show both the most important KPIs involved that led to the suggestions. This can create a positive feedback loop from the users that helps creating ever more effective features for future tuning
Using data democracy in the long run: empowering the end users
Almost no model can be considered a final version: there is always room for improvement! Either new data sources, features that came from experience and applied usage feedback or new ways of looking at existing data means that a machine learning project is part of a continuous improvement process.
After all, data democratization is not just about giving end users access to the data or provide them reports, powerpoints and dazzling dashboards. It is also all that of course, but there is more.
Data democratization is all about impact. No matter how accurate your model and how complex your dataset is, it's all for nothing if the end users cannot easily act on the provided information and readily give feedback on what works, what needs to be improved and where more explanation is needed.
This means that there are several layers to consider:
- Access to data, both raw and ready datasets are useful in order to both enabling collaboration on feature engineering and finding the best way to make actionable information
- To work with data it's extremely important to provide the right tools: this means putting emphasis on flexibility, ease of use and ease of sharing. Low code or no-code tools are the best way to reach an audience that mostly uses Excel so that there is as little friction as possible, transforming your users into Citizen Data Scientists wherever possible
- Every business unit should be engaged on this process. No matter if marketing, sales, product development or customer care, all can contribute on their domain and data scientists can greatly benefit from better understanding process funnels
- Finally, building a business culture revolving about using data to solve issues and finding solutions is necessary for long term success. Data scientists should be part of business talks and not relegated as a data Deus ex machina to be called only when standard solutions fail. At the same time, business users should be free to ask any kind of data question and trained on how ask questions about data and on how to translate business phenomena into variables
Conclusion: Empowering all data workers creates more than the sum of the skillsets
This is of course a very quick overview about how providing data literacy to domain experts and data democratization can help businesses grow and solve challenges. There is no step by step system on how to achieve this and a lot depends on starting conditions and IT architecture, however in the medium term (3 to 5 years) collaboration brings benefits that no data science team alone can guarantee, improving performance, actionability and ensuring business-wide support when it comes to add new data sources to machine learning models.
In my personal experience using this approach I've seen model performance go over 3X the starting model and giving up to 50% better results than what a data science team using the latest features selection libraries and up to date machine learning algorithms could achieve alone.
All in all, we could sum it up this way:
- A data science team alone can achieve good results but it would focus on raw data and tend to overprioritize linear correlations to the target variable
- Domain experts by themselves will focus on process and common sense variables, relying on feedback from the operations but unable to see wider trends on data
- Collaboration from the two will bring unexpected variables and a better understanding of both data and business environment, creating high performing, actionable models
No comments:
Post a Comment